Utilizing Java
So far we have utilized a custom defined parser built on the ElementTree library to parse xml files. This has worked well and helped explore the structure of WITSML files - however it is time consuming and can't capture the full nuances and features of the WITSML format. As previously mentioned Energistics maintains the WITSML library and is responsible for new versions of WITSML standards. It is therefore best practice to utilize a package which utilizes the latest WITSML standards.
Energistics maintains a SDK for developers written in C++ (https://www.energistics.org/standards-devkit/). In addition to this SDK, hashmapinc has also written a WITSML library in Java (https://github.com/hashmapinc/WitsmlObjectsLibrary), which can be used to parse files. This is great as we can utilize Java to promptly convert WITSML files into another format and feed this information into our Python data science work. The github page contains the maven project which can be used to parse WITSML data and is fully documented which is great.
As a quick reminder - lets connect to the azure data storage and analyze a WITSML file quickly.
# Import required libraries & packages
from azure.storage.blob import BlockBlobService
import pandas as pd
import xml.etree.ElementTree as ET
from bs4 import BeautifulSoup
from collections import defaultdict
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import os
import glob
# List the account name and sas_token *** I have removed the SAS token in order to allow the user to register properly thorugh Equinor's data portal
azure_storage_account_name = 'datavillagesa'
sas_token = '~'
# Create a service and use the SAS
sas_blob_service = BlockBlobService(
account_name=azure_storage_account_name,
sas_token=sas_token,
)
filename = 'WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1'
blob = sas_blob_service.list_blobs('volve', filename)
for x, b in enumerate(blob):
print(b.name)
if x > 10:
break
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/_wellboreInfo/NO 15_$47$_9-F-4 (dbffce7a-74d8-4443-8b7e-b937e5fede95)(NULL).xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/1.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/2.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/3.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/4.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/MetaDataFileInfo.txt
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/log/1/1/1/00001.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/log/1/1/1/00002.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/log/1/1/1/00003.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/log/1/1/1/00004.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/log/1/1/1/00005.xml
WITSML Realtime drilling data/Norway-Statoil-NO 15_$47$_9-F-4/1/log/1/1/1/00006.xml
Connect to log file and inspect element tags
WITSML_file = 'WITSML Realtime drilling data/Norway-StatoilHydro-15_$47$_9-F-14/1/log/1/1/1/00001.xml'
blob = sas_blob_service.get_blob_to_text('volve', WITSML_file)
soup = BeautifulSoup(blob.content, 'xml')
set([str(tag.name) for tag in soup.find_all()])
{'commonData',
'creationDate',
'curveDescription',
'dTimCreation',
'dTimLastChange',
'data',
'dataSource',
'direction',
'endIndex',
'indexCurve',
'indexType',
'log',
'logCurveInfo',
'logData',
'logs',
'maxIndex',
'minIndex',
'mnemonic',
'mnemonicList',
'name',
'nameWell',
'nameWellbore',
'pass',
'priv_dTimPriority',
'priv_dTimReceived',
'priv_ipLastChange',
'priv_ipOwner',
'priv_userLastChange',
'priv_userOwner',
'runNumber',
'serviceCompany',
'sourceName',
'startIndex',
'typeLogData',
'unit',
'unitList'}
If you recall, when we built our custom WITSML parser we generally only utilized mnemonicList (for column names), unit (for units per column) and data (containing the log data). Clearly there are a large number of fields which were neglected. For the most part - and for the purposes of exploring the data, these three columns will suffice - however there can be a large number of reasons why including additional fields will enhance the exploration of the dataset.
Below we will build the maven project from the hashmapinc repo and then utilize log files to convert witsml to csv enabling data science ingestion and workflows. Follow the instructions to build the maven project - also a decent idea to create the documentation. These are fairly simple operations given the provided instructions (and prerequisite installation of jave/maven/etc). After finishing the maven build there should be a java project with the following architecture:
Clearly there are a large number of packages that can be used to manipulate WITSML data. Most of what we will do will be captured in the WitsmlMarshal.java file which enables serialization and deserialization of witsml data objects - exactly what we need in order to read in WITSML data and parse it correctly! There are a couple of example scripts on the HashMap git repo to transform a WITSML file into a csv. We will get started doing that here. Listed below is one such method to ceate a csv from a 1.3.1.1 witsml log object:
public void testExportCSV1311(){ try { //read in witsml data String data = TestUtilities.getResourceAsString("log_with_data_1311.xml"); try { //create the version transformer WitsmlVersionTransformer transformer = new WitsmlVersionTransformer(); //convert to 1.4.1.1 String convertedData = transformer.convertVersion(data); //deserialize the data ObjLogs logs = WitsmlMarshal.deserialize(convertedData, ObjLogs.class); //get the csv String csv = LogDataHelper.getCSV(logs.getLog().get(0), true); } catch (TransformerException e) { e.printStackTrace(); } } catch (IOException | JAXBException e) { e.printStackTrace(); } }
In order to get started we will create a new java project and import the compiled WISTMLOBJECTSLIBRARY into this project as a dependency so we can use the classes and methods contained. We've gone ahead and initialized an empty java project folder structure and added the dependency in the pom file:
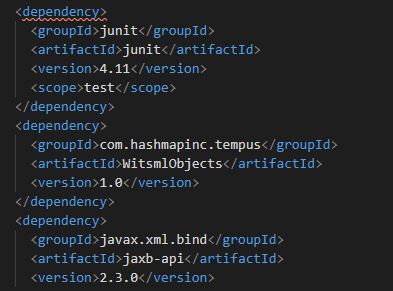
With the dependency, we can then import the associated classes/methods from the WitsmlObjectsLibrary and utlize it to read in and convert WITSML data objects.
Using the sample scripts available at the github repo, we will create a Parser.java file inside our new project that uses the testExportCSV1311 method. Copied below is the code contained in the Parser.java file - placed in the src/main folder:
package com.olsonfactory;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.io.FileWriter;
import java.io.BufferedWriter;
import javax.xml.bind.JAXBException;
import javax.xml.transform.TransformerException;
import com.hashmapinc.tempus.WitsmlObjects.Util.*;
import com.hashmapinc.tempus.WitsmlObjects.Util.WitsmlMarshal;
import com.hashmapinc.tempus.WitsmlObjects.Util.log.LogDataHelper;
import com.hashmapinc.tempus.WitsmlObjects.v1411.ObjLogs;
public class Parser {
public Parser() {
// No-op
}
public void testExportCSV1311(String fileName) {
try {
//read in witsml data
String data = getResourceAsString(fileName);
try {
//create the version transformer
WitsmlVersionTransformer transformer = new WitsmlVersionTransformer();
//convert to 1.4.1.1
String convertedData = transformer.convertVersion(data);
//deserialize the data
ObjLogs logs = WitsmlMarshal.deserialize(convertedData, ObjLogs.class);
//get the csv
String csv = LogDataHelper.getCSV(logs.getLog().get(0), true);
String csvFileName = fileName.replace("xml", "csv");
writeStringToFile(csv, csvFileName);
} catch (TransformerException e) {
e.printStackTrace();
}
} catch (IOException | JAXBException e) {
e.printStackTrace();
}
}
public void testExportCSV1411(String fileName){
try {
//read in witsml data
String data = getResourceAsString(fileName);
//deserialize object
ObjLogs logs = WitsmlMarshal.deserialize(data, ObjLogs.class);
//get csv
String csv = LogDataHelper.getCSV(logs.getLog().get(0), true);
String csvFileName = fileName.replace("xml", "csv");
writeStringToFile(csv, csvFileName);
}
catch (IOException | JAXBException e) {
e.printStackTrace();
}
}
public String getResourceAsString(String resourceName) throws IOException {
String path = "src/main/resources/" + resourceName;
return new String(Files.readAllBytes(Paths.get(path)));
}
public void writeStringToFile(String csv, String fileName) throws IOException {
String path = "target/" + fileName;
BufferedWriter writer = new BufferedWriter(new FileWriter(path));
writer.write(csv);
writer.close();
}
}
This defines the methods we will use to convert our file. We then create another file which will call these methods on the associated file.
package com.olson;
//import the parser class we previously defined
import com.olson.Parser;
public class App {
public static void main(String[] args) {
String TEST_FILE = args[0];
Parser parser = new Parser();
parser.testExportCSV1411(TEST_FILE);
}
}
In order to call this method, we would open a terminal, navigate to the project folder and run the following command:
java -jar target/witsmlparser-1.0-jar-with-dependencies.jar 00001.xml
The above command will read in the 00001.xml file (from weeks 2 & 3). It is presumed in this example that 00001.xml file is placed in the resources folder of the java project architecture. Calling this command places a csv file in the target folder of the project. We can then read this csv file into a pandas dataframe:
df = pd.read_csv('target\\00001.csv')
df.head()
| Time | CEMTEMPOUT | CEMSTAGE | STRATE2 | HKLD | CEMPUMPPR | STROKESUM | CEMFLOWINC | STRATE3 | PUMP | ... | CEMWTIN | STRATE1 | CEMWTOUT | CEMFLOWOUT | EditFlag | CEMIVOLPUMP | CEMTVOLPUMP | CEMTEMPIN | CEMCVOLPUMP | CEMFLOWIN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | unitless | K | unitless | Hz | N | Pa | unitless | m3/s | Hz | Pa | ... | kg/m3 | Hz | kg/m3 | m3/s | unitless | m3 | m3 | K | m3 | m3/s |
| 1 | 2016-09-30T10:04:00.000Z | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 128066 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2016-09-30T10:04:10.000Z | 0 | 0 | 0 | 392945.29 | 118088.1 | 0 | 0 | 0 | 124673.01 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 2016-09-30T10:04:20.000Z | 0 | 0 | 0 | 654267.78 | 197140.71 | 0 | 0 | 0 | 121374.61 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 2016-09-30T10:04:30.000Z | 0 | 0 | 0 | 654267.79 | 196218.3 | 0 | 0 | 0 | 122941.55 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 28 columns
Here we can see the file is correctly parsed, the first row (index 0) is a unit row, so it would be better to read this in differently. One method would be to include the first and second row as the header - we will also read in the time data as index and convert to timestamp format:
df = pd.read_csv('target\\00001.csv', header = [0,1])
df[('Time', 'unitless')] = pd.to_datetime(df[('Time', 'unitless')])
df = df.set_index(('Time', 'unitless'))
df.head()
| CEMTEMPOUT | CEMSTAGE | STRATE2 | HKLD | CEMPUMPPR | STROKESUM | CEMFLOWINC | STRATE3 | PUMP | CEMCUMRETURNS | ... | CEMWTIN | STRATE1 | CEMWTOUT | CEMFLOWOUT | EditFlag | CEMIVOLPUMP | CEMTVOLPUMP | CEMTEMPIN | CEMCVOLPUMP | CEMFLOWIN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K | unitless | Hz | N | Pa | unitless | m3/s | Hz | Pa | m3 | ... | kg/m3 | Hz | kg/m3 | m3/s | unitless | m3 | m3 | K | m3 | m3/s | |
| (Time, unitless) | |||||||||||||||||||||
| 2016-09-30 10:04:00+00:00 | 0 | 0 | 0 | 0.00 | 0.00 | 0 | 0 | 0 | 128066.00 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0 | 0.0 | 0.0 |
| 2016-09-30 10:04:10+00:00 | 0 | 0 | 0 | 392945.29 | 118088.10 | 0 | 0 | 0 | 124673.01 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0 | 0.0 | 0.0 |
| 2016-09-30 10:04:20+00:00 | 0 | 0 | 0 | 654267.78 | 197140.71 | 0 | 0 | 0 | 121374.61 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0 | 0.0 | 0.0 |
| 2016-09-30 10:04:30+00:00 | 0 | 0 | 0 | 654267.79 | 196218.30 | 0 | 0 | 0 | 122941.55 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0 | 0.0 | 0.0 |
| 2016-09-30 10:04:40+00:00 | 0 | 0 | 0 | 658498.46 | 196340.41 | 0 | 0 | 0 | 124673.01 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0 | 0.0 | 0.0 |
5 rows × 27 columns
Now we still retain the units - so that we can correct them if necessary - however all of the dataframe contains the data from the log file. We can then generate simple plots as we have done before to explore the data:
plt.figure(figsize = (15,5))
sns.lineplot(df.index.values, ('PUMP', 'Pa'), data = df)
plt.show()
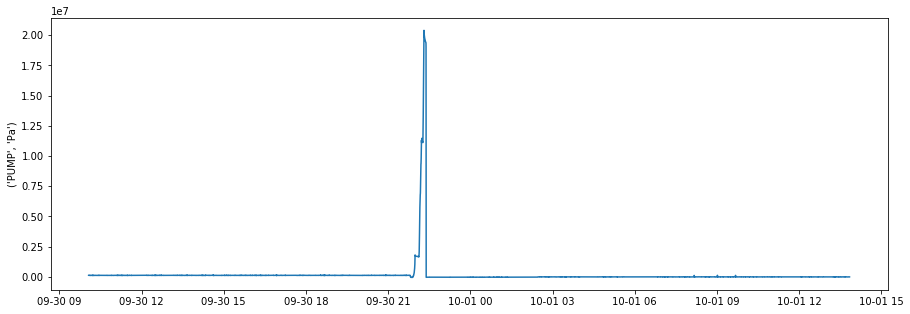
The file that we converted appears to be related to a cement job, whre the pump variable is the pump pressure (unit Pa). As can be seen - the pump presure was zero for most of the job, and then peaks presumably as the cement stage is pumped.
So this is great! We now have a way to more reliably convert WITSML data into csv which then we can ingest into our data science routines and practices. What would make the process better however - would be to conduct all operations in python, rather than having to manually run the java command on a specific witsml file.
Listed below, is a way to call the java process from within python, we can then automate this with a loop for all of the discovered wistml/xml file types when exploring the data blob. Alternatively, we can edit the java code to read in a file (text file) where each line is the directory for a new file to be read. One additional method would be to incorporate the string as read via blob storage and feed this directly into the java call - rather than having to download the witsml file.
We will start on the first. We can call java processes using the subprocess library. The procedure is relativley straight forward and mimics the terminal call we used earlier:
import subprocess
import os
import sys
env = dict(os.environ)
filepath = 'WitsmlParser\\witsmlparser\\'
os.chdir(filepath)
subprocess.call(['java', '-jar','target\\witsmlparser-1.0-jar-with-dependencies.jar', '00001.xml'], env = env)
0
Running this code uses the filename as the last argument and places the csv in the target folder. Essentially we can loop over this subprocess call to convert all wistml files into a csv.
In this weeks example we have utilized the WitsmlObjectLibrary written in java and available here: https://github.com/hashmapinc/WitsmlObjectsLibrary to read in witsml data and store it as a csv. This enables us to more reliably parse the witsml data files we have and convert them into a format useable for data science routines!
With this automated, we can now perform a deeper dive into the EDA, looking at multiple wells and trying to understand the Volve field - rather than a specific well (or log) within the field.