About
Introduction & Intent - about me and about the blog
My name is Aaron Olson - I've been in the oil and gas industry for 8 years now working on rigs, in the shop developing new tools to meet the needs of a changing industry, in the office coordinating the collection and integration of data from across North America, and in basin trying to make sense of the data in order to tell a story. Oil and gas has always had the challenge of solving a puzzle with limited and often mishapen puzzle pieces as we try to discern the environment 10+ thousand feet underfoot.
I got my start in the oil and gas industry near the shale boom in North America. When I started on the rigs I enjoyed watching the ever-scrolling data channels on a Pason display depicting output from sensors located throughout the rig (pressure, flow rate, bit depth, hole depth, etc) and trying to understand what these puzzle pieces were saying: were we drilling efficiently, were we out of zone, was the bit damaged, etc.
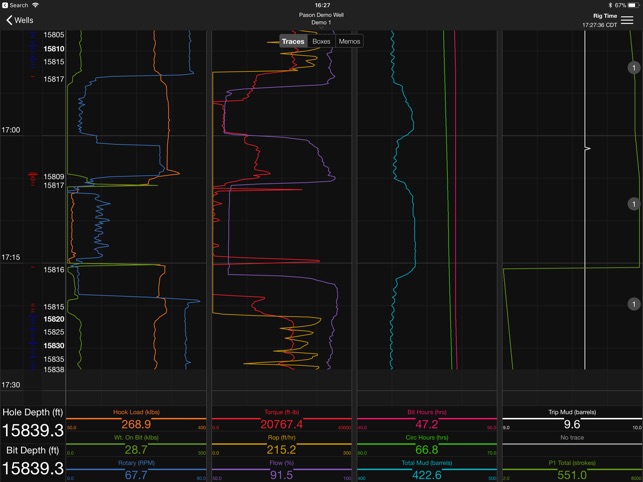
I first got started in data science when trying to take lessons learned on one well on the pad and applying it to another well - comparing results in an effort to derive if the changes made actually produced improved results? Or can improved performance be related to something else. For example if our production section was drilled with a 6 blade bit on well 1 and a 5 blade bit on well 2 and we saw improved performance on well 2 - can that be attributed to the bit? Were we drilling in a better section of the target zone that allowed for improved rate of penetration? Are there other factors (drilling parameters, BHA selection, etc) that may have also impacted performance? With on-shore wells costing multi-million dollars to construct and each well only drilled once (hopefully) - the cost of not learning from this data can be enourmous - but challenges frequently make this difficult:
- How do we attribute performance to one of many design changes between wells
- How can the data be captured in a format/way that is most beneficial for ingestion and learning
- What database structure can retain as much data as possible while also easily query-able
- How can as much of this as posslbe be automated?
In 2016 I was accepted into the Data Science masters program and am set to graduate in May/2020. Throughout this program I've been exposed to a number of data science techniques and technologies that can help (but also can confuse). In 2017 I graduated from Heriot Watt where my thesis combined these two fields of study looking at shocks and vibration in the Permian Basin. It was particularly important here to tease out what variable change correlated with the shocks and vibration that were observed downhole while drilling.

Today through my education and experience I incorporate data science into oil and gas datasets to improve our current performance and learn from mistakes that have been made. This includes ingestion of data and storage in time and depth based databases for quick query. Utilization of time series data and machine learning models to help learn from the data. Providing a business intellegence platform from the data to help show improvement trends, track KPI's and focus development where there are gaps. Additionally I enjoy the integration of physics based results and models along with the data. Many times there has been exceptional modeling effort in an attempt to explain what is happening down-hole. Data Science shouldn't treat this physics based model as an adversary - but should integrate alongside it, incorporate its relults and either calibrate the model or expand on what physics can predict to show what is actually happening. The domain based knowledge that has been collected the previous century of drilling is exceptional - utilizing domain specific knowledge with data science can help to develop explainable and accurate results from the dataset under investigation.
Big Data / AI / Machine Learning are certainly (and have been) buzz words in the industry now for several years - some projects have helped moreso from a research aspect on batch prepared data. But there is still such a gap in learning and utilization of this data on the development side, understanding what it means and creating best practices and lessons learned to continue to progress. I believe one of the key barriers to entry is ingestion of the data from oil and gas specific file types, as well as an easy way to store and query this data. If the data can be accessed more easily - providing the high level plots, reports, KPI and ML models can be relatively routine (this simiplifies it a bit - all of these can be exceptionally detailed - but gathering the data and making it useful will likely always be 80% of the effort of a finished product - and generally is no fun).
I've started this blog to help lower these barriers and provide examples of integrating data science and oil and gas. The intent is to show examples of key problems and work through the exploratory data analysis, handling of missing/innacurate/etc data, storage and domain type of data and finally learning from the data.
Hopefully by exposure to integration of data science and O&G data - the barriers to entry can be lowered and the use and utilization of each well's data can properly be used and learned from.
I continue to be challenged day to day integrating solutions to better understand what the puzzle pieces say and truly enjoy working the problem to identify what the data has to say. The title of the blog 'From Bitumen to Binary' not only in the popular phrase that data is the new oil - but the value obtained not only in that fundamental petroleum component - but the value that can also be extracted by means of the data created to capture the petroleum.
The goal of the blog will be to release a new notebook weekly. I have chosen the Volve field as the primary dataset which Equinor recently released. This data has been made freely available (after registration) in order to learn from the development and production of an oil field. Each week will involve a new problem associated with understanding the Volve field - hopefully developing an additional piece of the puzzle that can be used to learn from the past.
I hope you enjoy and if there is a specific topic/challenge/etc that you have and we can work through together - please make note in the comments and I will try my best to develop a notebook addressing that issue.